
Don’t link directly to misinformation sites

Archiving, tracking and annotating can help you avoid directing traffic to malicious actors
The views expressed in this column are those of the author and do not necessarily reflect the views of the Reynolds Journalism Institute or the University of Missouri.
I often hear from journalists that misinformation is a “fact-checking problem.” The answer to incorrect information is to correct it, right? Shouldn’t journalists simply correct the record? Unfortunately, a bevy of research has shown that misinformation is a much more insidious dilemma. The same journalists who are correcting the record are often, inadvertently, also spreading the information they’re trying to debunk.
Misinformation researcher and RJI Fellowship alum Barrett Golding wrote about this issue on his website Iffy.news. “Major news outlets are key contributors to clickbait’s booming business,” he wrote. “Their direct links to fake-news stories boost ad revenue and SEO for misinformation.”
Last month, the Associated Press wrote a story on Children’s Health Defense, an anti-vaccine misinformation purveyor. In 2020, the AP found, the group’s revenue more than doubled – at least partly due to its success in circulating its anti-vaccine claims among social media and on mainstream news. “While many nonprofits and businesses have struggled during the pandemic,” the article said, “Kennedy’s anti-vaccine group has thrived.”
So what should journalists do about it? For one thing, Golding proposes a newsroom-wide guide for reporters so they know which sites to link to, and which to avoid. “Publishers should adopt a link policy — guidelines for when and how their writers should link to external sources,” he wrote.
Golding’s site Iffy.news, which attempts to find and catalog “fake news” sites, does not link to those sites directly. Instead, the Iffy.news team will link only to more credible sites, and use a web archive link for the malicious actors.
There are many tools out there for archiving and screenshotting, which in turn allow you to display a site without it earning page views, but only a handful come up again and again. The first and the most famous is one you’ve probably heard of – the Internet Archive, also referred to as the Wayback Machine or archive.org.
The Internet Archive aims to do exactly what it says: save a copy of the Internet. That’s a big task, so you’re not going to find archived versions of everything. But you can use the site – or its browser extension – to save a copy of a webpage right as you’re looking at it.
This means you’ll be able to look at it again later, along with a date and timestamp of when it looked that way. It also adds the page to the giant repository of Internet Archive content, which is good for web openness and transparency.
A similar tool is Archive.is, which I see becoming more commonly used. Archive.is is a simple technological tool for archiving a page then and there. It also offers a browser extension and a connected Android app, Save2Archive. One downside of Archive.is is that it sometimes takes a few minutes to complete its archiving process.
A third option for the simple task of finding an archive is Google Cache. A cache in this case is a version of a website or webpage that got saved by another website – often a search engine. Among other things, Google uses caches to access websites that are down, and make search requests run faster.
Sometimes, even if a file was edited or deleted, you can look up the cached version and save or link to that. Unfortunately, you have to be lucky (or quick) enough to catch the cache just at the right moment. For instance, the cache I found of TFR’s Twitter feed hadn’t been updated in five days.
Other archiving tools like the Wayback Machine are much more comprehensive, but they might not have captured, say, a tweet right before it was deleted or a webpage right before it was edited. A cache is another way to avoid directing traffic to a malicious site and has the added benefit of offering a neat investigative tool.
Archiving pages, like Google Cache, Archive.is and the Internet Archive, is a simple way to snapshot a website and avoiding linking directly to it. Other tools offer much more in-depth functionality. Many of them are meant for other industries like academics and law enforcement.
One of them is Hunch.ly. It’s a paid tool for online investigations, meaning some of its main users are investigators and members of law enforcement. It’s a rather expensive tool at $129/year, but you can get a 30-day free trial.
Hunch.ly is much more ambitious than the simple archiving tools. It stores copies of every page you visit while you have it turned on, including things like private social media pages. This way you don’t need to keep track of where you go and how you got there. Nor do you need to worry about things like bios changing or profiles getting deleted.
Another tool that I’m fond of is called Hypothes.is. In addition to copying a webpage onto its own site, Hypothes.is encourages you to annotate it. You can highlight text and even images to leave notes, which can add a layer of transparency and clarification for your readers.
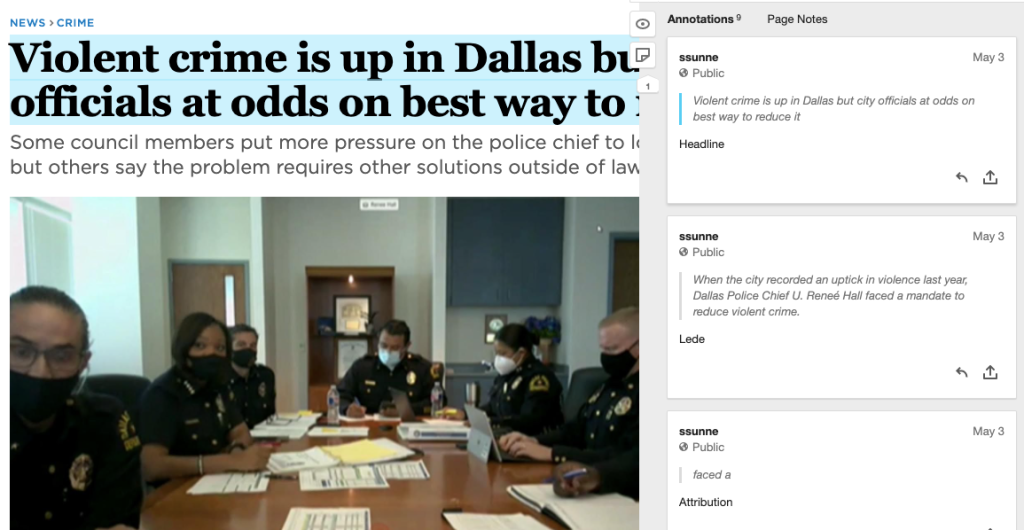
It can also be a good tool for sharing your research with colleagues or editors. Instead of simply sending them a link, you can share a detailed breakdown of why you think the page is worth mentioning. Plus, you know the link and the content on the page isn’t going to change, because it’s been saved on the Hypothes.is platform.
These more advanced tools offer additional layers of archiving and tracking that can make your reporting more thorough and transparent. But even if you don’t do a lot of online investigation, tools like the Wayback Machine browser extension make it easier to avoid linking directly to misinformation sites. This way we avoid directing traffic, and therefore an amount of income, to sites that we’re actually trying to debunk.