
The Public Media Careers homepage, created by Alex Curley.
Creating a directory of job listings for public media

A conversation with Alex Curley
Through Semipublic, which provides data and insights about the public media industry, Alex Curley aims to track public media’s hiring patterns and condense the data into an easily digestible format. With a recently launched job listings aggregator, Public Media Careers, Curley hopes to help job seekers navigate the changing public media industry.
Innovation in Focus student staffer Ishrat Madiha spoke with Curley about the process for creating this database and the tools for putting it all together.
Madiha: What inspired you to create a product for entry-level jobseekers and what elements were most important in regards to that?
Curley: I had a difficult time breaking into the public media industry when I had just graduated college and having a website that I knew for sure reflected every open position available across the country would have been super helpful.
It was important to me to collect and include data points that are most useful to job seekers right now, other than the obvious ones like title, company, etc. Based on user feedback, those data points were job location (as in remote, hybrid, or on-site,) the seniority level of the position and compensation expressed as a yearly salary.
Madiha: What was the process for creating Public Media Careers?
Curley: Public Media Careers was originally born out of a completely different need: I wanted to be able to track public media’s hiring patterns, so I began scraping job listings from every public media-specific jobs board. When I was creating the scrapers for the job boards, I realized that the fact that I had to scrape listings from 15 different websites created a classic product problem to solve. I already had the job listings in a database, Postgres, so I decided to make a website that displayed them in a simple format, which is now public media’s only industry-specific jobs listings aggregator.
Madiha: What tools did you use to help you and how do each of them assist you with the final product?
Curley: n8n is probably the tool I use most for my work. It’s basically a visual interface to automate tasks. With n8n, I scrape websites to extract data from, I clean up data and place it in the correct database, I compile specific data about public media stations using LLMs, I generate notifications about my websites and automations, and it even runs essential functions for some of my websites. When I am starting a new project, I’m usually gathering data as a first step and the first tool I go to is n8n, which I self-host on a server in my house.
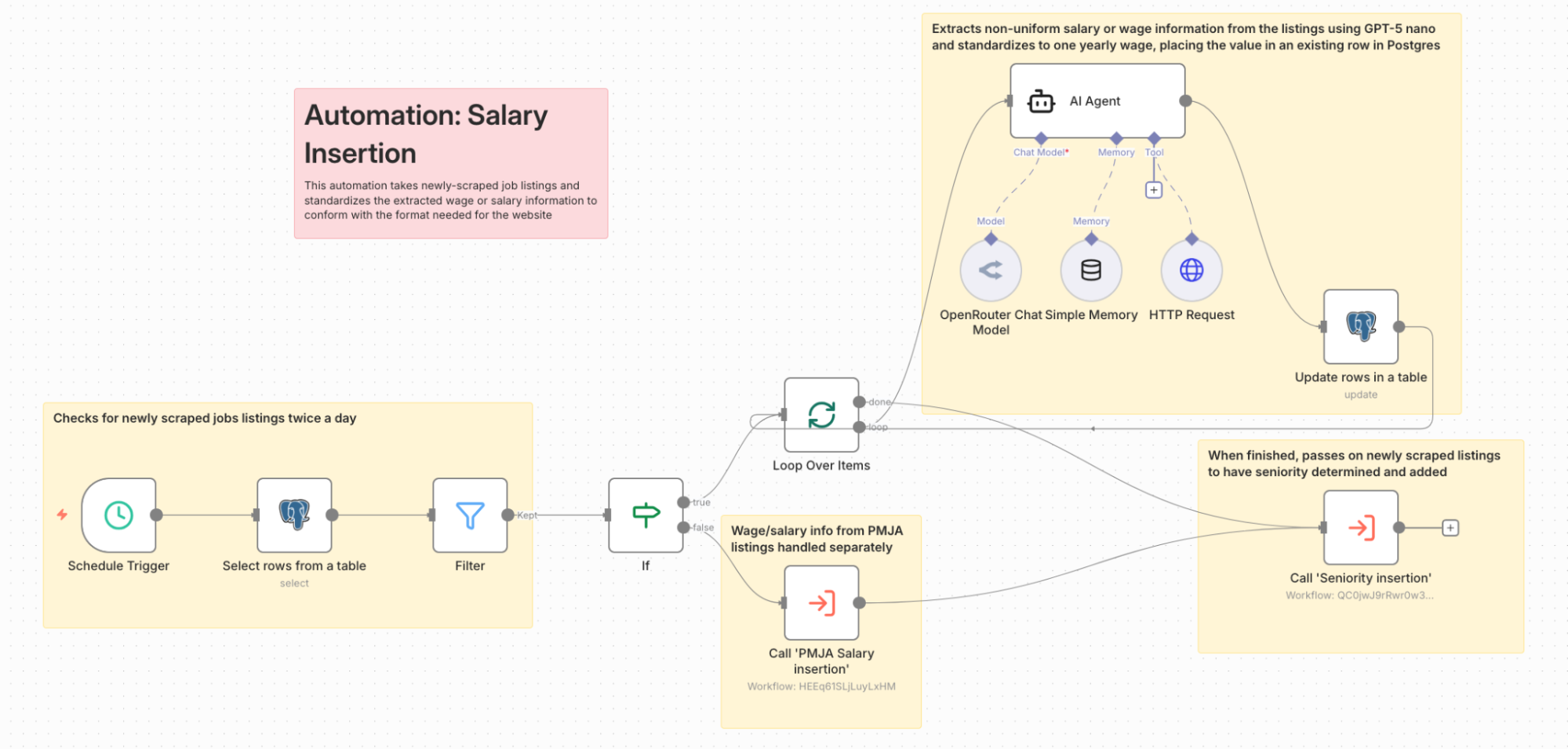
Postgres, which I also self-host on a server in my house, houses the foundational databases I’ve built Semipublic and Adopt A Station on. All of my n8n automations first place data into my self-hosted Postgres server. It’s locked away from the outside world (except a few tools like n8n) so that if anything ever happened to my public-facing services or sites, my core data won’t be affected.
I use Supabase, which is basically a fancy wrapper for Postgres, to house my databases for public-facing apps and websites. It has a generous free tier, user friendly options and robust privacy options that make it easy to connect apps or websites to it via API calls.
I use Cloudflare Tunnels to handle making services that are self-hosted accessible on the web. They have an incredibly generous free tier with a lot of really useful features; it’s not a surprise that half the internet runs on their services.
I use Docker (run on Debian servers) to host Postgres and other services from my house. To make the websites, I used a combination of bolt.new, Magic Patterns, and Claude Code.
Madiha: What were the difficult parts of putting this directory together?
Curley: The hardest part of creating the jobs website for me was the user design. Job listings contain a lot of data in a simple package, and making sure that the data I was including was both useful and uniform was challenging.
Madiha: What would be your advice for people making directories or listings– especially for those in smaller newsrooms and/or that have minimal technical skills?
Curley: Make sure you can get the data first, and make sure you can gather data with as little human intervention as possible. Make sure you scale the work of whatever product you’re looking to build appropriately with the amount of risk you’re willing to take. My jobs website runs almost 100% by itself; the only human intervention it requires is to check a few unforeseeable errors. Make sure you’re either filling a large hole in the market or have a real, demonstrable user demand.
Editor’s Note: This interview has been edited for clarity and brevity.

Sign up for the Innovation in Focus Newsletter to get our articles, tips, guides and more in your inbox each month!
Cite this article
Madiha, Ishrat (2025, Dec. 10). Creating a directory of job listings for public media. Reynolds Journalism Institute. Retrieved from: https://rjionline.org/news/creating-a-directory-of-job-listings-for-public-media/