
Building simple data pipelines
It’s important to be able to deploy scrapers that will continue to scrape and store your data without you having to prompt them every time.
For journalists looking to stay on top of COVID-19 trends, access to data from state and county health authorities is crucial. However, this data can often feel inaccessible, existing behind dashboards and other interfaces. And once you get to it, scraping the data is only half the battle. It’s important to be able to deploy scrapers that will continue to scrape and store your data without you having to prompt them every time.
As we’ve worked to collect various COVID-19 metrics for local newsrooms, we’ve developed a recipe for a relatively simple Python data pipeline. While there are many ways to approach this problem, we’ve found this method fairly easy to implement and sufficient to get the job done.
Scraping
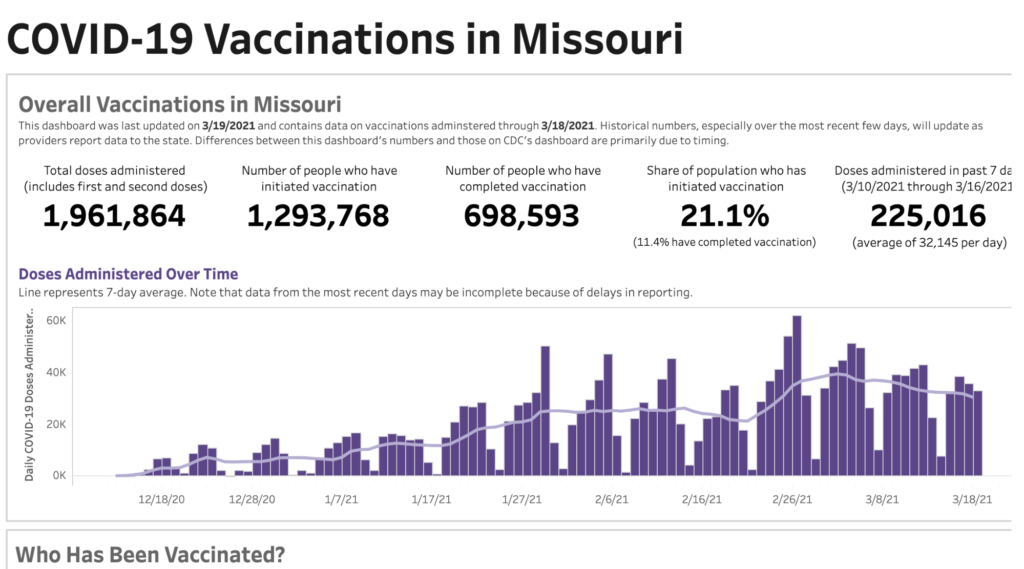
Our most recent application of this pipeline involved scraping and storing vaccination data from Missouri’s vaccination dashboard. The dashboard was built in Tableau, and unfortunately scraping Tableau dashboards often isn’t very straightforward. Luckily, we were able to use a Python library called TableauScraper that did most of the heavy lifting for us.
To store our data, we created an AWS Simple Storage Service (S3) bucket. The boto3 Python module, made to create, configure, and manage AWS services, allowed us to interact with this bucket (as well as other AWS services) directly from our Python scripts.
You can also enable versioning on S3 buckets. Versioning makes it easy to manage different versions of your data files. So as we write over existing files in the bucket with new data, file versions of the previous data are stored in case we need to access them again. Bucket versioning allows you to keep your bucket cleaner and more organized, which is especially useful if you have scrapers running frequently.
Deploying
Next we uploaded our code to an AWS Lambda function where we set it to run every hour. To use libraries such as TableauScraper (or Pandas) with Lambda, we first had to create a Lambda layer which lets us package those libraries along with our script.
This project also served as our first foray into the world of GitHub Actions, a feature that made the continuous integration of our project easy to implement.
We were able to create a workflow such that every time we pushed code to the master branch of the remote repository, that code would be packaged and shipped to our Lambda function so that it was always running the latest version of our scripts.
Finally, to make the data easy for other journalists to access, we built a simple static web page that lists all of the available datasets and the different versions of each set.
Final steps
Once you’ve developed a data pipeline recipe that works for you, it is a good idea to make a project template that will allow you to create and deploy new data pipelines for future projects within minutes.
We’ve found success with Python’s CookieCutter library for our templates. This library allows you to specify a project template. Then every time you want to start a new project, you clone that template, fill in a few fields and it will automatically generate your basic project structure. If you’re comfortable writing shell scripts, you can also use CookieCutter to automate the creation of your AWS S3 bucket and Lambda function using the AWS command line interface.
Jacob LaGesse is a Discovery Fellow at the Reynolds Journalism Institute. He is a computer science major at the University of Missouri, and is tracking COVID-19 with the New York Times.