
Photo: Erfan Parhizi | Unsplash
Your first web-scraping project will be easier than you think

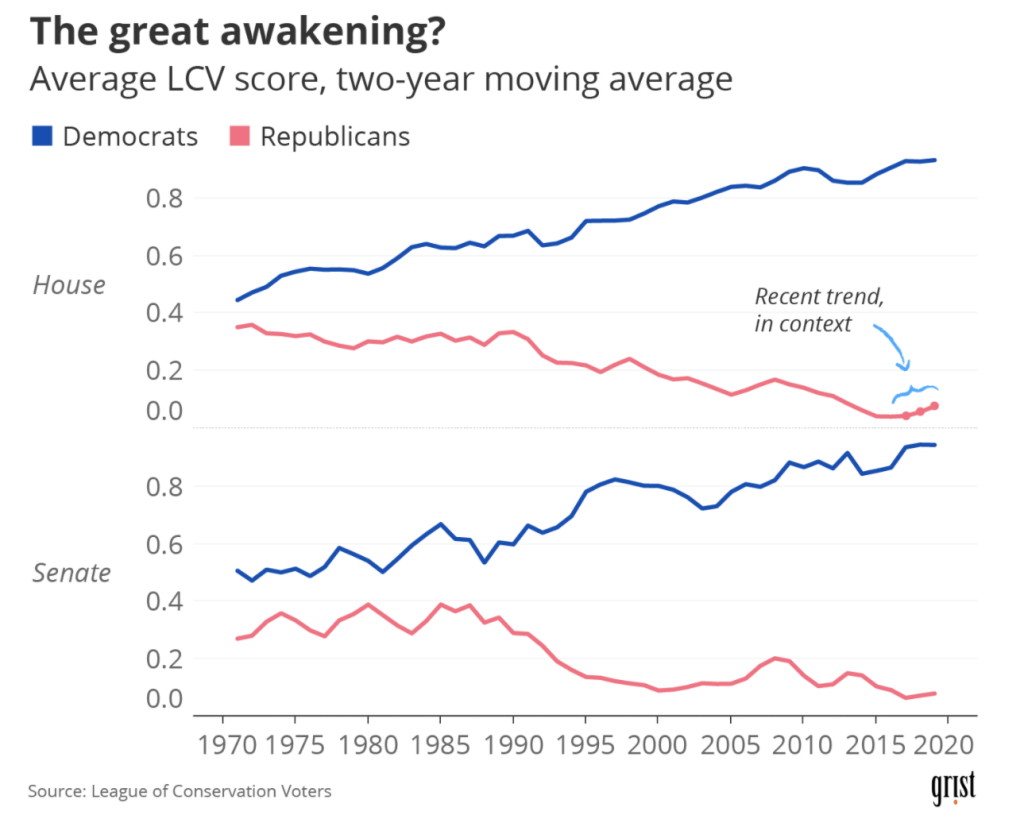
Last week, a colleague emailed me with a data request. She was working on a story about the shifting sands of Republican congressional rhetoric on climate change and was wondering if GOP voting records had seen any corresponding shifts in recent years. She pointed out that one good measure of environmental voting comes from the League of Conservation Voters, which has published environmental scorecards for every member of Congress since 1970. Could we compare a couple years’-worth of data?
Well… sure! Given the whole dataset, it’d be a straightforward enough task to track the party’s average LCV score over time. But we don’t actually have the whole dataset. We have annual tables from the dataset (published freely online!) spread across multiple web pages:
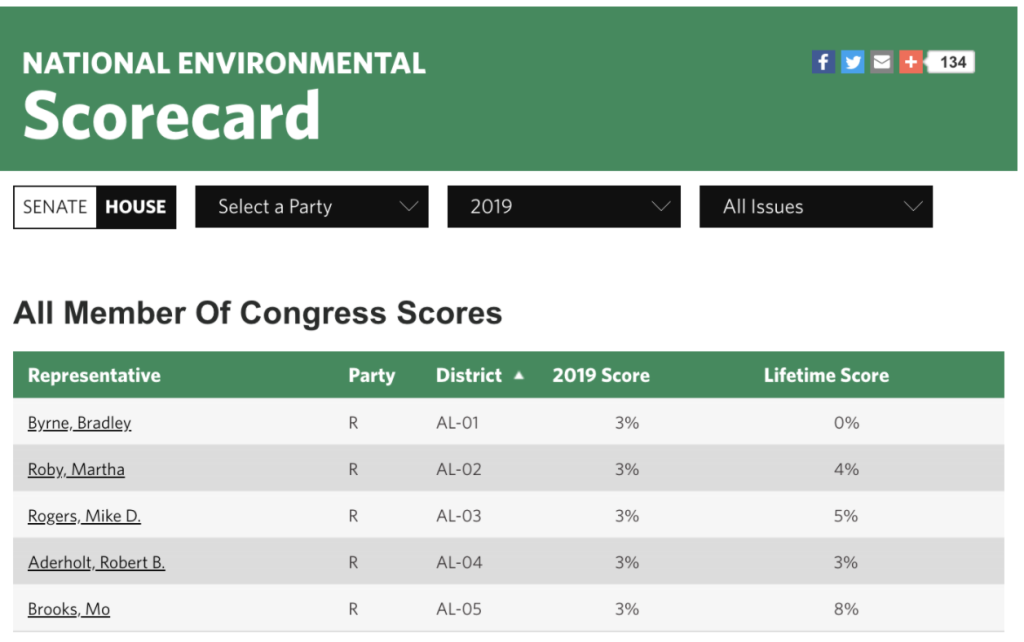
It’s a good excuse to write a simple web scraper—and a great excuse to write about web scraping to share with you. Though the phrase might conjure up images of hooded basement hackers and towering server farms, in practice, scraping is a core tool of contemporary data reporting. And given the computing tools of today, a lot of scraping jobs amount to just a couple lines of code. Let’s walk through what it’d take to accomplish the task outlined above.
Note: This post is most appropriate for journalists who know a little Python—or at least have poked at it once or twice! If you’ve never used Python before, I recommend Google’s quick two-day class.
To scrape or not to scrape?
Before we get started, a quick word on the legality and ethics of scraping (which require much more than a quick word —perhaps the subject of a future post). The long and short of it is that you can quickly find yourself working in a legal grey area here, mostly because there’s not enough legislation or case law on the books explicitly concerning web scraping. But there’s a little bit. Late last year, for example, the Ninth Circuit ruled in favor of a small analytics company that scraped publicly accessible data from LinkedIn, which had filed a cease-and-desist order over the practice.
Also worth a read is this amicus brief the data journalism outfit The Markup offered in a case currently pending in front of the Supreme Court. While the case in question doesn’t concern scraping per se, it pivots on an interpretation of the Computer Fraud and Abuse Act that could have huge implications for scraping-based data reporting. Again, it’s outside the scope of this post to dive into the details here, but the gist of the amicus is that web scraping constitutes a routine newsgathering exercise that’s protected under the First Amendment. (Arguments are set to be heard this November.)
My two cents: If your target data are already publicly available on a given website, and all you’re doing is automating the process of extracting what you could readily extract (slowly) by hand, then you’re probably fine to scrape. A best practice: Read the terms and conditions of a given website first and/or take a look at the site’s robots.txt file, which you can find by adding a /robots.txt to any URL and which should offer the general terms with which a robot (like your scraper) can engage with the site’s content. In the case of the LCV Scorecard’s robots.txt file, it looks like they disallow scraping of various user data and backend file systems. Fair enough! We won’t be grabbing anything like that.
Beautiful, BeautifulSoup
We’ll gloss over a couple subtle points for the purpose of this tutorial, but I’ve posted the full code here if you’d like to follow along. The main point I’d like to illustrate is that when you’re faced with a data table like the one at the top of the post, behind that table is often some well-structured HTML code, which we can restructure accordingly for our own purposes. To take a look at the code behind the table in question, use your browser’s Inspect tool by right/two-finger clicking on a table element and choosing “Inspect” from the pop-up menu. You should see something like the following (minus my annotations):
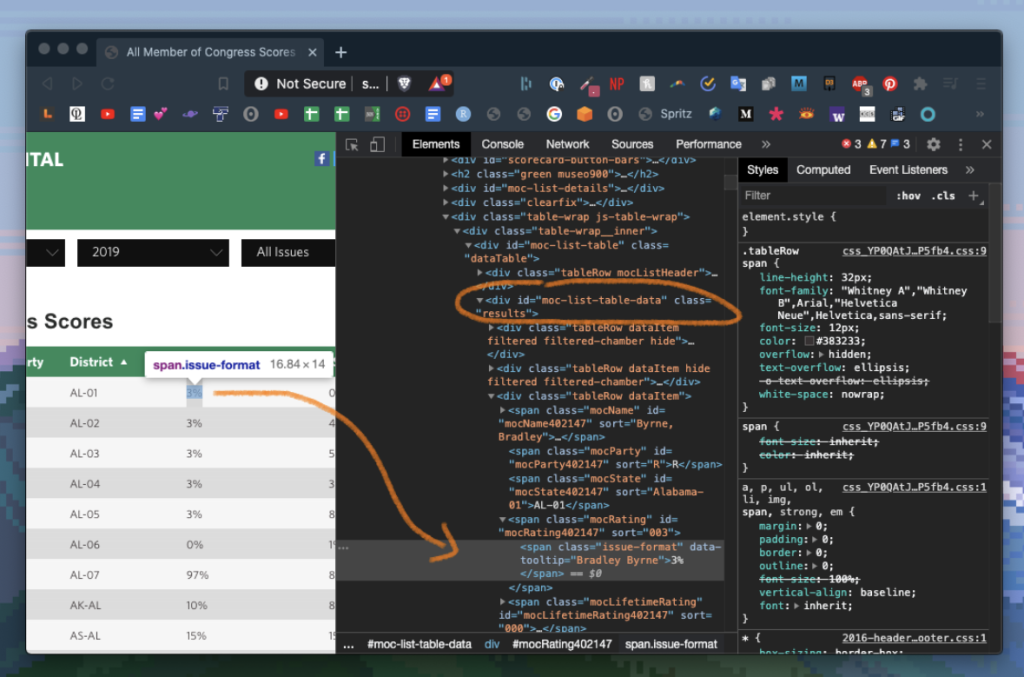
It looks like each of these rows belong to an HTML class called “tableRow,” each of which are contained in the larger element called “moc-list-table-data.” We want to hoover up all the tableRows in moc-list-table-data, parse them accordingly, and get on out of here.
To do so, we’ll turn to the BeautifulSoup library, a collection of Python functions that make HTML-parsing as easy as… soup? Not sure about the etymology here. The point is: Install the bs4 library, import BeautifulSoup (along with the ‘get’ function from the requests library), get the page source code, and then parse the code with BeautifulSoup’s namesake and find/findAll functions:
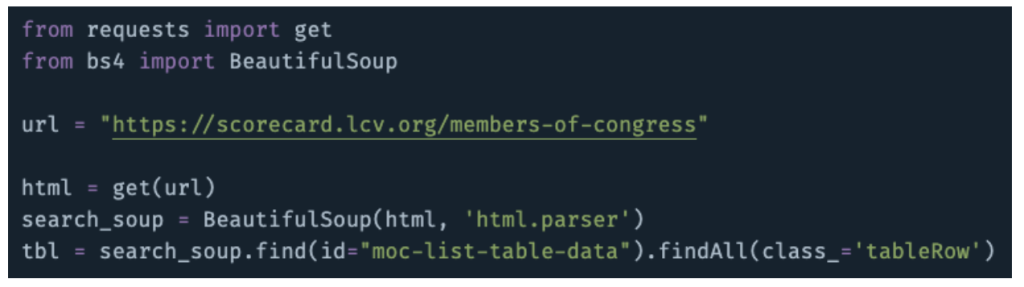
I wish it were more complicated than that—could be useful for job security—but it’s not. We’ve now got the whole table stored in the tbl variable. To turn this object into something we can readily export and analyze, let’s loop through it and store it in a pandas DataFrame. We know the class names of each of the relevant elements here because we already peeked behind the scenes with the Inspect tool!
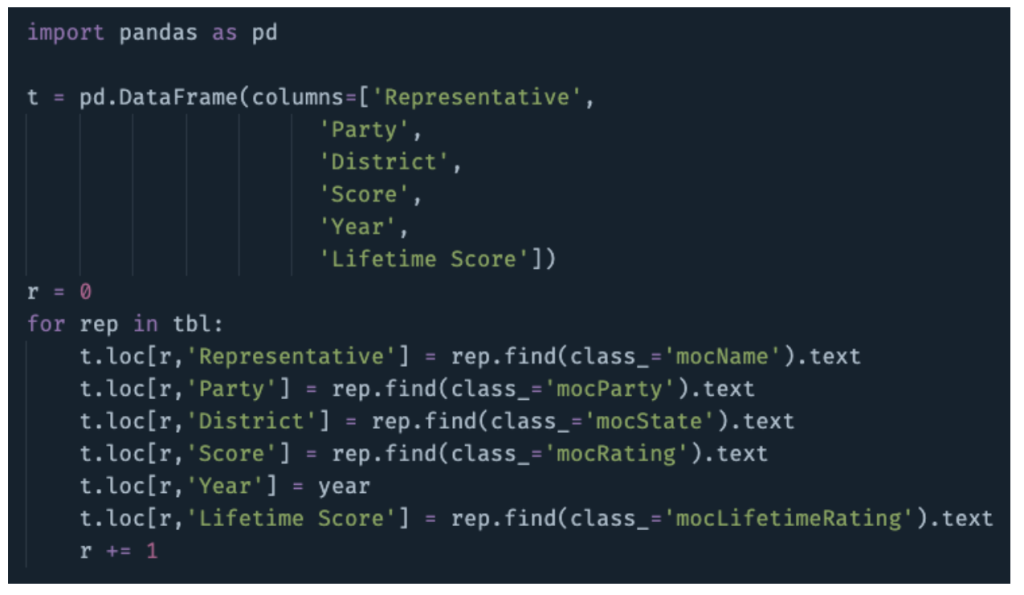
And that’s that.
Though if you’re paying close attention, you’ll have noticed we haven’t yet defined the ‘year’ variable we call in that portion of the script. That’s because I’ve snuck ahead a bit in the code to get to the meat and potatoes of the whole affair. So far, we’ve only got one year of data. What about the rest of them?
Turning up the volume with Selenium
BeautifulSoup was helpful for snagging and parsing the source code for one page. To get at the rest of the data, though, we’ll need to use the ‘Year’ dropdown menu to select a new year (so the on-screen table will update accordingly). And that means we’ll need a tool for interacting with web browsers.
Today, we’ll use the Selenium library to launch and control a Chrome browser. After disabling some web security settings—check out the GitHub repository for the relevant code here—we’ll activate a chromedriver (install that!) and select the dropdown menu. As previously, we can find the codename of the menu by selecting it with our browser’s Inspect tool. Let’s store a list of all available years in a variable called ‘options’ and then make the dropdown menu selectable by our scraper using Selenium’s Select function:
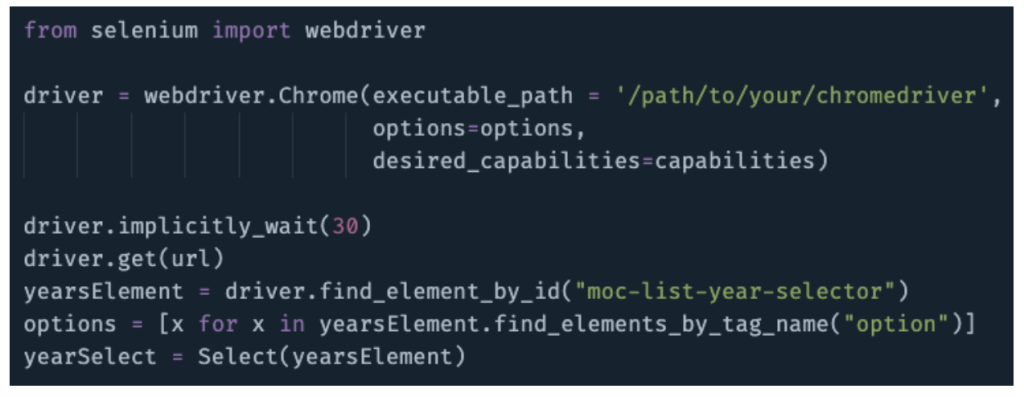
Once the menu is selected, it’s just a matter of looping through our options (years), letting the page load, and pulling the resulting source code. We’ve already written the rest of the scraper with BeautifulSoup!
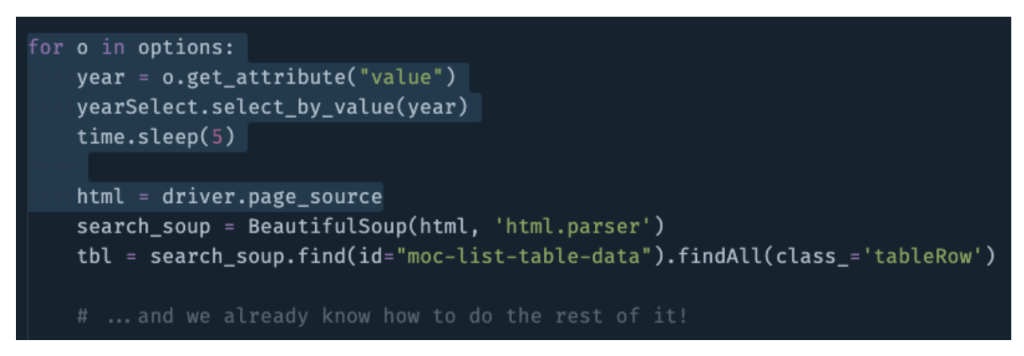
As you loop through the pages, just make sure you append each new table to a master table variable—you don’t want to overwrite your work each time. Otherwise… that’s it! What do we have here; 20 lines of code? Hardly basement hacking. Run your scraper, grab a Gatorade, and return well-hydrated to your squeaky-clean data table.
What are you scraping? You can get in touch with Clayton Aldern at caldern@grist.org or on Twitter @compatibilism.