
Image: DNY69 | Canva
How to conduct a DIY algorithm audit


Six steps to produce newsworthy findings that promote algorithmic accountability
In 2019, Matt Tracy, a reporter at Gay City News (who’s now its editor-in-chief) began noticing how often Google News seemed to highlight homophobic and transphobic content as news. Disturbed by the apparent slant in promoted stories, he decided to systematically investigate the influential news aggregator’s LGBTQ news recommendations.
This story he published summarized the findings of his five-day study: “Google has been prioritizing some of the web’s fringiest alt-right, anti-gay news websites in search results related to LGBTQ news content.”
Tracy’s report exemplifies what we describe here as a DIY algorithm audit. With the increasing prevalence of online recommendation systems, algorithm audits have emerged as “one of the most popular approaches to algorithmic accountability.”
But what is an algorithm audit? And how do journalists like Tracy, who are interested in pursuing stories of online bias, conduct audits of their own? We address these questions and outline a six-step framework for conducting DIY algorithm audits.
What is an algorithm audit?
In its most basic form, an algorithm audit is a method of repeatedly varying inputs to observe an algorithm’s outputs. There are many different types of algorithm audits but nearly all share one or two common goals, to draw conclusions about an algorithm’s inner workings and/or its potentially problematic outputs.
Here we focus on a do-it-yourself (DIY) algorithm audit, characterized as a primarily qualitative assessment that does not require technical computational skills, and which you can carry out yourself.
Constructing a DIY algorithm audit
1. Determine the focus of your investigation
Define a subject that is specific and researchable. You should determine whether it will be possible to measure differences in outcomes.
For example:
- Differences across groups: such as if you aim to research bias based on gender, race, sexuality, or other forms of identity
- DIfferences across content categories: such as if you aim to determine how recommender systems impact news distribution.
To produce a newsworthy finding, you need to be able to define what a normal or unbiased result would look like. See Cathy O’Neill’s work on explainable fairness for one detailed framework; though we also appreciate the elegant simplicity of the recommendation, by Pratyusha Kalluri, who advises, “Don’t ask if AI is good or fair, ask how it shifts power.”
By researchable we mean that you can access the algorithm in question and manipulate inputs to document outputs. Typically this means selecting one or more of the most prominent search engines, news aggregators, or social media platforms—that is, systems intended for public use that employ algorithms.
2. Time frame
When will data collection begin and end? How frequently will you collect data? The scope of the project—including the time and staff required to conduct it—will be influenced by answers to these questions. With limited time and working solo, our experience is that meaningful results can be generated based in as little as one week of data collection. (Analysis and write-up may take longer.)
For some audits, an important event—such as the passage of important legislation—can serve as a temporal anchor for determining when to begin and end data collection.
3. Engine/browser configuration
It’s easy to take for granted how the configuration of your search engine and web browser may bias your findings. To minimize personalization there are multiple options:
- Use a web browser with no user history and do not log-in
- Use Tor (a browser that blocks all trackers and ads) for this purpose
- Use a VPN allows you to select a server in a different location, which can help avoid results tailored to your actual geographic location or previous browsing history.
Even if you use a VPN (and especially if you don’t) it’s good practice to regularly clear your browser’s cache, cookies, and history to avoid these impacting your search results.
If you are investigating how a search engine works, it’s often useful to compare results from two or more systems. This is one way of establishing a baseline for your investigation, as advised in the section on determining your research subject.
4. Search terms
Developing search terms is key to conducting an effective algorithm audit and should be driven by the issue that you are looking to investigate as well as the platform(s) being audited. Whether your focus is on how certain groups of people are portrayed on news aggregator platforms, how often harmful stereotypes appear in search results, or how search engines prioritize certain types of content or sources over others, your search terms need to align closely with your objectives.
As a starting point, you’ll want to use broad search terms. Consider the types of words that the general population might use when they are searching for information online, as well as synonyms and related concepts.
Once you’ve developed search terms, run queries on the platform to gain a better understanding of how the search engine or platform organizes, prioritizes, and surfaces information.
Make note of biases or patterns that may surface as you are developing and testing your queries. Broaden or narrow the search terms as needed—even minor tweaks can potentially surface stereotypes or other problematic content related to historically marginalized groups, or content likely to be subject to online filtering. Document the process and rationale behind the development of your search terms to ensure transparency and reproducibility.
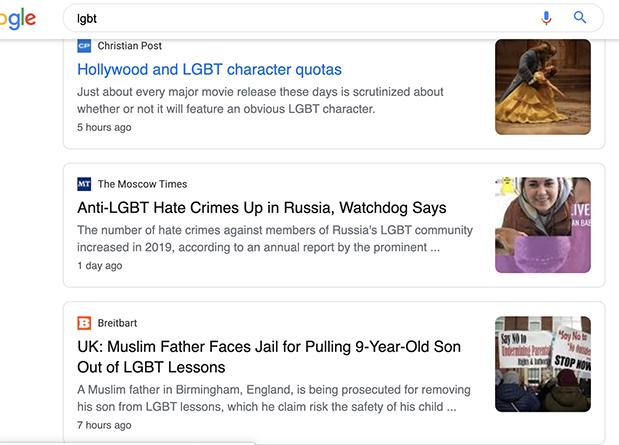
5. Data collection
The simplest form of data collection involves submitting queries manually and saving the results. For an audit of recommendation results this could be as simple as saving screenshots for subsequent analysis. Note if the output is organized into different components and how these are positioned relative to each other. For each result, also note the search terms you used and the date (and time of day, if collecting multiple times per day).
If you intend to examine results in more depth, we recommend creating several collection folders, including one for screenshots of output and another for any more detailed content associated with each result. Collecting more detail than you may eventually use is less frustrating than being forced, at a later stage in the auditing process, to go back and retrieve details you did not realize would be necessary for analysis.
One limitation to manual collection is scalability. Collecting and recording results manually is not difficult, but it takes time and patience. Jack Bandy and Nicholas Diakopoulos describe how they conducted a crowdsourced audit of Apple News. Danaë Metaxa and his colleagues offer guidance on more technical, automated forms of data collection. It is sometimes possible to use an application programming interface, or API, to automate data collection—but many of the most likely targets for algorithm audits have no public API or are built to resist data scraping. Some research suggests that APIs do not accurately represent actual user experiences, another reason to use them selectively.
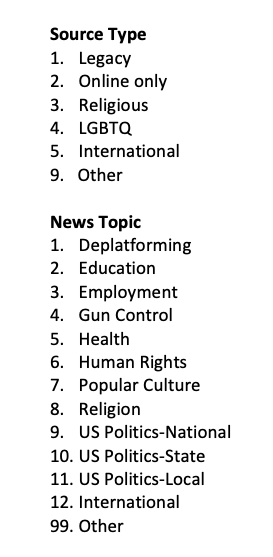
6. Data analysis
First, start your analysis with a valid baseline or comparison case.
Second, create coding categories to organize the data you have collected. The most rigorous coding categories are mutually exclusive: Each instance should only fit one coding category. But in practice this is not always feasible. Be ready for—and welcome—instances that create “trouble” for your coding categories by defying categorization. Don’t force them into existing categories; instead treat them as “boundary” cases that will help you refine your coding categories and enhance the validity of your findings.
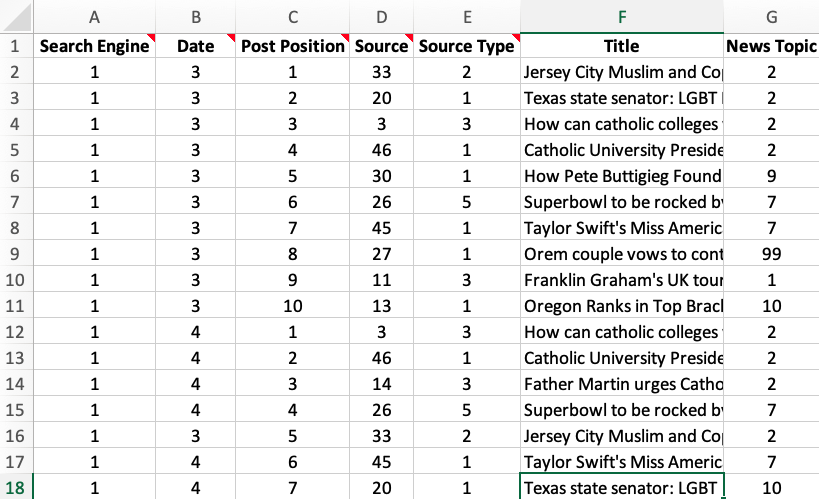
Keep track of your coding in a spreadsheet. Doing so will not only allow you to produce simple descriptive statistics, but also help remind you of individual results that can be presented as concrete examples.
Note patterns of outputs that depart from your established baseline or diverge significantly from your comparison case.
On completing an audit, draw conclusions with caution. Avoid overgeneralization. The performance of an algorithm in one specific context does not justify generalizations about how it will perform in other cases. Although small-scale audits like those recommended here can have “a large impact,” algorithms typically need to be monitored over time in order to fully understand how they are changing and evolving.
Why do an audit?
Most obviously and importantly, you can produce newsworthy stories based on algorithm audits. Many algorithm audits are motivated by concerns of bias in search or recommender systems, including recommendations that reflect or perpetuate what Aleksandra Urman and her colleagues, in a comprehensive survey of recent algorithm audits, described as discrimination and distortion. Notably they identified “news distribution” as one focus of critical attention.
An algorithm audit might expose anti-LGBTQ bias in the recommendations made by a news aggregator, as in Matt Tracy’s report and a follow-up study that we conducted; or an algorithm audit could expose how a search engine unfairly promotes certain types of content, as Adrianne Jeffries and Leon Yin documented in a report for The Markup about how Google search boosts Google products.
Algorithm audits are one practical response to the “black box problem.” Despite claims of transparency, the Big Tech companies that develop and manage algorithms frame responsible use as “an issue of closed-door compliance rather than a matter of public concern,” as P.M. Krafft and colleagues noted in an article about creating an action-oriented AI policy toolkit for community advocates.
But Alphabet, Meta, and other Big Tech companies are unlikely to act on ethical critiques of their algorithmic systems unless they face public pressure. As epitomized by one respondent to a survey of individuals and organizations engaged in algorithm audits, “The best way to make sure that the issue is attended to is to have the press report on it.”
Beyond the audit
Although algorithm audits can stand on their own as a basis for newsworthy reporting, impactful reporting often combines an audit’s findings with conventional interviews. Interviewing people—including not only those who developed or use a particular algorithm, but also those who are impacted by it—is a fundamental aspect of algorithmic accountability reporting, which can provide “high-level insights” into how an algorithm works and its impacts. For example, Marta Ziosi and Dasha Pruss interviewed a diverse group of stakeholders, including community organizers and residents, who identified algorithmic biases in a crime prediction tool used by Chicago police and, based on their findings, advocated for criminal justice interventions.
Cite this article
Roth, Andy Lee; and anderson, avram (2024, Sept. 4). How to conduct a DIY algorithm audit. Reynolds Journalism Institute. Retrieved from: https://rjionline.org/news/how-to-conduct-a-diy-algorithm-audit/