
How I preserve user privacy in the YESEO bot

Breaking down each bot command with the privacy, data and share options
When building a tool for public use, we need to think about the possible consequences. How could someone use our tools or resources in ways we didn’t intend, and what are possible consequences?
I listened to feedback and in December debuted this new /prep command for my YESEO bot, where you can enter a story before publishing and are able to get a SEO keyword analysis of it. When introducing newsrooms to test this feature, the question I continually got was “can anyone access my unpublished work?”
Of course my answer was “no”, but the question being asked meant that I wanted to make sure processes were in place to ensure it. And broadly speaking, how could I make sure to keep users’ data as private as possible, while also using it in the bot to help journalists do their jobs better?
Ensuring privacy at the start
The YESEO bot only allows existing links to be seen by users who are utilizing the bot. So if I enter a link to an already published story about a snowstorm and a user searches the “snow” keyword, they could find it. But if I paste in story text (in the pre-publishing feature) about a rain storm and a user searches “rain,” they won’t be able to find it.
I wanted to use this as an opportunity to emphasize privacy and show how I am working to protect data, what data I am collecting and how I am using it to help users and the bot service overall.
When you use this bot, you may enter commands, click on buttons that lead to links in the browser, or even click on other buttons that lead to even more functionality.
When those events happen, I am collecting data such as the name of the workspace where the bot is installed, what command or button click was used and where the link went to from a user. When you use the new Chat GPT-3 solution to ask for recommended headlines and descriptions, I track the button to keep records of how many requests are being made, which will help me estimate how many tokens to budget for when people start using it.
/analyze
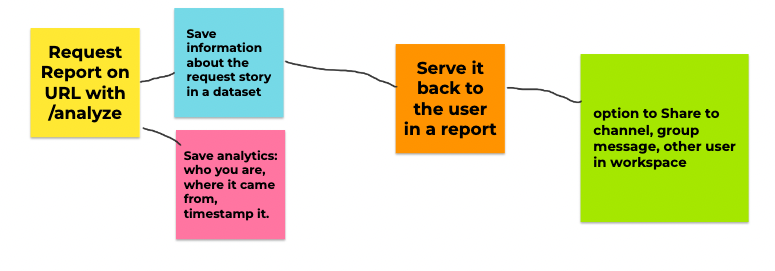
When a user enters /analyze and pastes a URL, the initial data being collected is an output Slack makes on the request. It includes data like:
- the name of the workspace
- where the message came from
- the name of the user who sent the message
- what command they used
- what text they entered.
This is stored in a separate dataset and timestamped so it can be used to track how often users are visiting and what they are running for analysis. If a user finds an issue, these will be useful to figure out what went wrong.
How are shares tracked?
In testing early on one useful feature is this new sharing button. I currently only include it on the /analyze command where there is already existing, published content.
This allows you to share the SEO report you see in your Slack channel directly into a public or private channel, a direct message or group message immediately. From there, any of the buttons would also be clickable to show the group results from the report. This helps share SEO findings across your team or company, without multiple people having to run the same command on a story.
The share message in my code only refers to the types of messages possible to be opened (direct messages, channels, etc.), it has no idea about any of the channel names or users in the display you see.
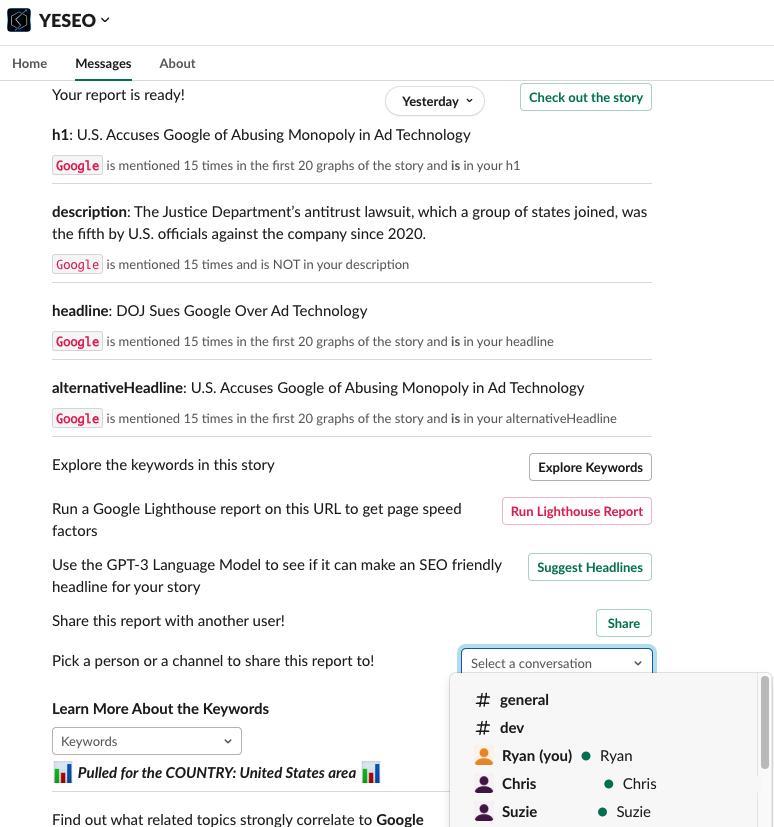
Even though the button shows a list of users you have interacted with and channels, none of that is being stored by the bot. Slack is grabbing that from your existing chats and channels and surfacing where it thinks you may want to share it to.
The only data I see on my end is what you clicked so the app can facilitate the message into that channel. And once shared, that channel has full access to the report.
/prep
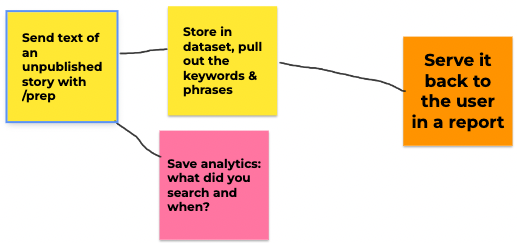
The /prep command talks to its own separate database for unpublished items. It runs similar reports, but all messages and words pulled from the story are stored in this data document.
The keywords get linked into the keyword database, since they are where all keyword reports are generated, but they cannot be requested by any user who didn’t enter the command.
I have not yet included the share button to the /prep command to ensure privacy, but would like to know from users how they feel about whether they would want to share results of this command across their workspace.
/popular and /lookup

Since all the keyword data is compiled and added to, based on all links entered by all users of the bot, a new feature is using the keywords to serve more data across the bot to all the users. With /popular (and /lookup) it’s possible to look at other reports in the system that were not entered by you.
But each of these reports that use the keywords dataset can only serve up existing links as buttons, which means only already published work entered by other users of the bot.
So any search of Southwest Airlines in the system can only yield stories that are already online.
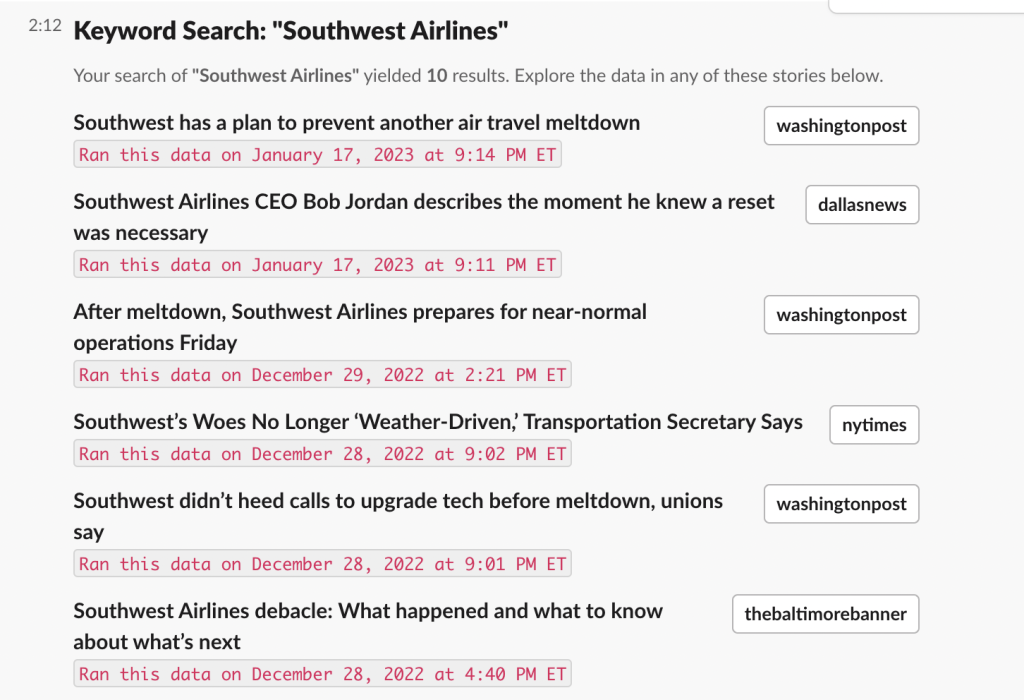
I have also been thinking through how to protect privacy in terms of data access. Since this data will continue to compile, ideally no user should have a right to access all of the data outside of the app. However, if someone wants to request their own workspace’s data, I will work to accommodate them by creating a report that can summon all of their raw data.
This is just part of what I have been working on in the late stages of this project, as Slack apps require privacy policies that explain how data is being collected and stored and I want all my users to be secure in the knowledge that whatever they entered in my bot, is as private and secured as I can make it.